
Elindult az Indamedia média és marketing-kommunikációs kiadványa.
További szakmai tartalmakért kattints és kövess bennünket!
MEGNÉZEM
Kövesse az Indexet Facebookon is!
Követem! AI-forradalmat ígérhetnek az Apple új M-szériás chipjei
AI-forradalmat ígérhetnek az Apple új M-szériás chipjeiHa a Facebooknál bejelentenek egy új fejlesztést vagy bemutatnak egy kutatási eredményt, az a közbeszédben jó eséllyel úgy csapódik le, hogy a cégnél újabb eszközt találtak arra, hogy még több mindent tudhassanak meg rólunk, amivel még több pénzre és még nagyobb hatalomra tehetnek szert. A gyanakvó távolságtartás indokolt is, nem véletlenül olvashatnak az Indexen is rendszeresen újabb és újabb adatvédelmi botrányokról vagy éppen az álhírek veszélyes terjedéséről. Az érem másik oldalán viszont a Facebook és a többi nagy techcég mára a technológiai fejlődés megkerülhetetlen bástyáivá nőtték ki magukat, ahol a világ élvonalába tartozó kutatók végeznek értékes tudományos munkát, olyan feltételek mellett, amilyenekről korábban álmodni se mertek volna.
Éppen e bizarr és kicsit félelmetes kettősség miatt ígérkezik mindig érdekesnek, ha lehetőség nyílik bekukkantani a színfalak mögé, megismerkedni a legújabb kutatásokkal, és meghallgatni, mit gondolnak minderről maguk a kutatók. Nekem nemrég a Google amszterdami központjában adódott ilyen alkalom, ezúttal pedig a Facebook mesterséges intelligenciára (MI) fókuszáló párizsi kutatólaborjába látogathattam el.
A több évtizedes múltra visszatekintő MI-kutatás az utóbbi időben a reneszánszát éli. Hogy miért éppen most, ahhoz tudni kell, hogy a „mesterséges intelligencia” nem egyetlen konkrét technológia, hanem sokféle kutatási irány összefoglaló neve. Az elmúlt néhány év leglátványosabb eredményei főleg a gépi tanulás nevű ágára épülnek. Ennek a lényege, hogy egy rendszert nem manuálisan programoznak be valamilyen konkrét feladatra, hanem sok-sok adattal tréningezik, hogy aztán önállóan is el tudja végezni a dolgát: képeket mutogatnak neki, hogy jobban felismerje, mi van a fotóinkon, szövegekkel tömik, hogy pontosabban tudjon fordítani és hasonlók.
A gépi tanuláson belül is létezik többféle módszer, de a mostani fellendülés középpontjában a mélytanulás (deep learning) áll, amely az idegrendszer biológiai modelljéről mintázott neurális hálókra épül. A lényege, hogy a különböző típusú adatokat sok-sok külön rétegben dolgozza fel, amelyek egymásra épülnek (ettől mély). A képek esetében például a gép az egyszerűbb mintázatoktól a specifikusabb tulajdonságok felé haladva ismeri fel, hogy mit lát.
Ezek a mélytanulásos neurális hálózatok viszont iszonyatosan nagy számításigényűek. Ez az oka annak, hogy bár már régóta léteznek ilyenek, egészen a közelmúltig nem sokra mentek velük. Az MI-reneszánszhoz alapvetően három dolog kellett: egyrészt a szoftver, vagyis jó mélytanuló algoritmusok; másrészt rengeteg adat, amellyel ezek tréningezhetők; harmadrészt a hardver, ami elbírja ezeknek az algoritmusoknak a futtatását.
Bár ma már az okoscsapból is a mesterséges intelligencia folyik, ez még néhány éve se volt magától értetődő. A Facebooknál 2013-ban jött létre egy kifejezetten MI-kutatásra összpontosító hálózat, a Facebook Artificial Intelligence Research (FAIR), amelyben ma már Kaliforniától Montrealon át Tel-Avivig több helyszínen dolgozik nagyjából 250 kutató. A 2015 nyarán nyílt párizsi központ a legnagyobb FAIR-egység, a Facebook MI-kutatásainak európai központja. Több mint 80 kutató dolgozik itt, köztük körülbelül 20 PhD-hallgató szerte a kontinensről.

A FAIR olyan, mint egy akadémiai kutatócsoport. Az itt dolgozó kutatók elsősorban nem a Facebook termékein dolgoznak, inkább alapkutatásokat végeznek, amelyeknek az eredményeire később a termékeket építeni lehet. A mentalitás is ehhez igazodik: miközben a céget más téren az átláthatóság hiánya miatt kritizálják sokat, a FAIR eszközeinek nagy része – például a PyTorch nevű népszerű keretrendszer – szabadon hozzáférhető, a legtöbb eredményük nyilvánosan elérhető, és szorosan együttműködnek a cégen kívüli kutatói közösséggel.
Persze a FAIR mellett egy alkalmazott gépi tanulásos csoport is működik a Facebooknál, akik a közvetlen termékfejlesztést végzik. De a mesterséges intelligencia jelentőségét mutatja, hogy az ma már az egész cég működését átszövi. Ha megnyitjuk a Facebookot vagy az Instagramot, egy neurális háló dönti el, mi kerüljön elénk a hírfolyamban, gépi tanulás szabja személyre a látott hirdetéseket. MI segít szűrni – több-kevesebb sikerrel – az emberi ésszel felfoghatatlan mennyiségű új tartalmat, amelyet nap mint nap feltöltünk bejegyzések, képek, videók, kommentek formájában. Az egyre fejlettebb képfelismerő algoritmusok azonosítják a képen szereplő barátainkat, sőt az újabb fejlesztéseknek köszönhetően már a tárgyakat és épületeket is. A Portal nevű okoskamera is ennek köszönhetően tudja automatikusan követni a térben mozgó embert, és hozzáigazítani a képet. De a gépek teszik lehetővé a napi 4,5 milliárd automatikus fordítást a világ legkülönfélébb nyelvei között; így lehet a videókat automatikusan feliratozni a halláskárosultaknak; vagy így tudja a Facebook a fejlődő országokban párosítani a vérdonorokat azokkal, akiknek vérre van szükségük. És persze a Messenger-botok vagy a virtuális és kiterjesztett valóság se képzelhető el mesterséges intelligencia nélkül.
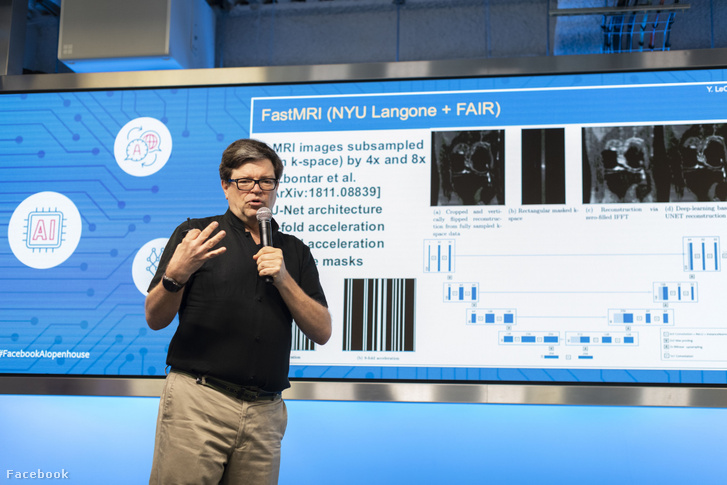
Ha kiveszed a mélytanulást az olyan cégekből, mint a Facebook és a Google, összeomlanak, mert ma már teljesen e köré épülnek
– mondta Párizsban Yann LeCun, a mélytanulásos kutatások egyik úttörője, a mai képfelismerő eljárások alapját jelentő neurális hálók egyik kidolgozója, aki két társával idén tavasszal kapta meg az informatikai Nobelként is emlegetett Turing-díjat. Ő azért jött a Facebookhoz 2013-ban, hogy létrehozza a FAIR-t, és ma már a Facebook vezető MI-kutatója.
Ha valaki csak ebből a cikkből hallott volna a Facebookról, eddig azt hihetné, hogy az egy idilli és gondtalan hely, ahol az egyre okosabb gépek a széltől is megóvják a boldogan netező felhasználókat. De aki használja is az oldalt – azaz úgy 2,4 milliárd ember –, az nagyon jól tudja, hogy ez távol áll a valóságtól: bár a Facebook egyre nagyobb energiát fektet a gyomlálásba, a gyűlöletbeszéddel, az álhírekkel és hasonló csúfságokkal még mindig meggyűlik a baja.
Az MI-nek fontos szerep jut a moderálásban, hiszen hiába dolgozik már 30 ezer moderátor a cégnél (nem éppen irigylésre méltó körülmények között), manuálisan lehetetlen feldolgozni az egyre szaporodó tartalmat. A gépnek ez nem probléma, a kapacitása szükség szerint bővíthető, képes akár minden egyes posztot átnézni. Az összes azonosított gyűlöletbeszédnek így ma már 65 százalékát mesterséges intelligencia szúrja ki.
Teljesen automatizálni azonban nem lehet a moderációt. A gyűlöletbeszéd definíciója közösségi sztenderdeken alapul, ezért folyamatosan változik, és ebből adódóan mindig tökéletlen – mondta Joaquin Quiñonero Candela, a Facebook MI-fejlesztési igazgatója. Még ha technikailag meg is lehetne oldani a dolgot, mindig igazodni kell az újabb és újabb társadalmi és szabályozásbeli elvárásokhoz. Jó példa erre a meztelenség kérdése: a gép gond nélkül felismeri, de az már nem technológiai kérdés, hogy mondjuk a szoptató anyák képeit tiltani kell-e az oldalon.
Az MI nem tudja meghozni ezeket a döntéseket, és nem is neki kéne meghozni
– mondta Candela.

A cél inkább az, hogy a hús-vér moderátorok összedolgozzanak a gépekkel, és mindenki azt csinálja, amihez a legjobban ért. A géptől elsősorban a priorizálást várják: azonosítsa azokat a posztokat, ahol emberi beavatkozásra van szükség, az egyértelmű esetekben pedig még azelőtt távolítsa el a problémás tartalmat, hogy az terjedni kezdhetne – ahogy például az al-Kaidához köthető tartalmak 99 százalékát ma már azelőtt kiszúrják, hogy az emberek elé kerülhetne.
Ez elvileg jól hangzik, de a gyakorlati problémákra megrendítően pontosan mutatott rá a márciusi christchurchi mészárlás, amelyet először élőben közvetítettek Facebookon (és Youtube-on), majd még napokkal később is újra és újra feltűntek a videó másolatai az oldalon, hiába harcolt ellenük tűzzel-vassal a cég. (Május közepén az élő közvetítésekkel kapcsolatban is szigorítást vezettek be a történtek hatására.)
A hasonló videók szűrése már régóta működő módszer, de ezt viszonylag könnyű a videó módosításával (újravágásával, croppolásával) kicselezni. Candela is elismerte, hogy ez a probléma még mindig megoldásra vár, de szerinte már most is sokat javultak a hasonló videók felismerésében. „Optimista vagyok, hogy ez technikailag megoldható, és egy év múlva már sokkal jobb lesz a rendszer abban, hogy felismerje a vizuálisan különböző tartalmaknál is a koncepcionális hasonlóságot, ezen most is dolgozunk” – mondta. Mások jóval kevésbé bizakodóak ezen a téren.
A Facebook próbálkozik a még teljesen ismeretlen terrorvideók azonosításával is, de ezt Yann LeCun szerint több tényező is nehezíti: egyrészt a felkavaró tartalom gyakran a videók hangjában található, nem a képen; másrészt – szerencsére – nagyon kevés eredeti adat, azaz lövöldözős videó áll rendelkezésre, amelyekkel az algoritmusokat edzeni lehet; harmadrészt ezeket a videókat meg kell tudni különböztetni a lövöldözős filmrészletektől és videójátékoktól is, hiszen ezeket hiba lenne kiszűrni.
A problémás tartalmak elleni szélmalomharc mellett a Facebook másik érzékeny pontja az adatkezelés. A cég iránti bizalomvesztés szintjét az az újra és újra felbukkanó összeesküvés-elmélet mutatja legjobban, amely szerint a Facebook azért tud rólunk ennyi mindent, mert a telefonunk mikrofonján keresztül titokban lehallgat minket. Bár ezt már mi is körüljártuk és cáfoltuk egy korábbi cikkben, megkérdeztem róla Jérôme Pesentit, a Facebook MI-ért felelős alelnökét is.

„Semmi ilyesmit nem csinálunk, ezzel kapcsolatban nagyon világosak vagyunk. Az, hogy újra és újra felmerül a gyanú, azt mutatja, hogy pontosak a következtetéseink, tehát ezek szerint jó algoritmusokat sikerült összeraknunk. De szerintem abban lehetnénk jobbak, hogy világossá tesszük, hogy milyen adatokat használunk fel, ezek hol vannak, törölhetők-e, illetve mit nyerünk ki belőlük, és azt hol használjuk fel” – mondta.
Az emberek alulbecsülik, hogy a viselkedésük mennyi mindent elárul az érdeklődésükről, és nem realizálják, hogy ebből valójában sokkal több minden kiderül, mint abból, hogy mit mondanak. Sokkal több a viselkedésükben a mintázat, mint gondolják.
A magánszféra védelmével kapcsolatos másik aktuális kérdés az arcfelismerés, amelynek a használatát épp május közepén tiltották be San Franciscóban. Yann LeCun egy ezzel kapcsolatos kérdésre elmondta, hogy a korlátozást jó döntésnek tartja, és az arcfelismerést a Facebooknál amúgy se nagyon kutatják már, mert szerinte ez technológiailag egy megoldott probléma. Igazán nagy léptékben nem tudják alkalmazni, de ez nem is céljuk, szemben mondjuk a kínai kormánnyal. Kínáról egyébként azt mondta, hogy a Facebook azért nem érhető el ott, mert nem akar hozzáférést adni a kínai kormánynak a felhasználók privát adataihoz.
Az olyan cégek, mint a Facebook és a Google – annak ellenére, ami az újságokban olvasható – extrém módon védik a felhasználóik adatait
– mondta, ami azért a Cambridge Analytica-ügy óta bátor állítás, még ha Mark Zuckerberg cégvezér nemrég nagy változásokat is ígért ezzel kapcsolatban.
LeCun nem ért egyet azzal az általános nézettel, hogy a mesterséges intelligencia további fejlődését a hardver korlátai tartanák vissza. A valódi korlátot szerinte az jelenti, ha nincsenek új ötletek: „Természetesen mindig szükségünk lesz nagyobb számítási teljesítményre. Vannak a szakmában, akik szerint csak növelni kell a kapacitást, hogy fejlődést érjünk el. Én nem így gondolom, szerintem a valódi előrelépéshez új ötletek is kellenek.” Ilyen, az egész MI-kutatást előremozdító új ötletnek tartja egy újfajta tanulási módszer előretörését.
A neurális hálók alapvetően háromféle módon taníthatók be. Ma a legelterjedtebb a felügyelt (supervised) tanulás, amikor a gépnek előre felcímkézett adatok alapján tanítják meg, hogy néz ki például egy repülő. A másik népszerű út a megerősítéses tanulás, amikor nem a feladat helyes megfejtését mondják meg a gépnek, hanem a jó megoldást jutalmazzák vagy a rosszat büntetik. Egyik módszer sem igazán hatékony: a felügyelt tanuláshoz rengeteg pontosan előkészített adatra, a főleg játékok betanítására használt megerősítéses tanuláshoz pedig rengeteg próbálkozásra, így hosszú időre van szükség.
LeCun szerint a mesterséges intelligencia kutatása egyre inkább a harmadik módszer, az önfelügyelt (self-supervised) tanulás irányába tolódik, és szerinte
ez lesz az MI-kutatás következő forradalma.
Az önfelügyelt tanulás hasonlít leginkább a megfigyelésen alapuló emberi és állati tanuláshoz, és bár a Facebooknál már egyre több feladatra használják, még nem sikerült megfejteni, hogyan lehetne igazán hatékonyan megvalósítani gépeknél.
„A Facebook párizsi és kaliforniai MI-csapatában is vannak kognitív és idegtudósok, akik az emberi tanulást vizsgálják. Nem tudjuk lemásolni az agyat, és valójában rossz stratégia is lenne azzal próbálkozni, hogy lemásoljuk minden részletét, mert nem értjük ezeknek a részleteknek a funkcióját” – mondta LeCun. Szerinte ez olyan lenne, mint repülőgépet fejleszteni tollas szárnyakkal: a tollak nagyon hasznosak a madaraknak, de nem feltétlenül szükségesek a repüléshez, inkább annak működési elvét kell megérteni és átültetni. Ez a céljuk az MI-kutatásban is: nem lemásolni akarják az agyat, hanem megérteni a működését, és megtalálni a gépi környezetben működő megfelelőjét.
Az elmúlt 4-5 évben ilyen modelleken dolgoznak, és szövegnél már elég jól működik szerinte a módszer. A lényege, hogy a gép ne előre megadott válaszok alapján tanuljon meg egy feladatot, hanem megfigyelés alapján próbálja meg kitalálni a megoldását. Ha például egy szövegelemző neurális hálónak mutatnak egy sor szót, amelyből néhányat kitakarnak, a többi szó jelentése és a szövegben betöltött szerepe alapján kell megjósolnia, mi hiányzik. A rendszer így képes megtanulni egy szöveg nyelvektől független reprezentációját, amely alapján aztán bármilyen nyelvre képes lefordítani az adott szöveget. Hasonló módszerrel próbálkoznak képek, videók, hangok esetén is, de még messze a teljes megoldás – mondta.
(Munkatársunk a Facebook meghívására és költségén vett részt a rendezvényen. A cikk enélkül nem készülhetett volna el, ugyanakkor teljes egészében szerkesztőségi tartalom, készítésére a cég semmilyen befolyással nem volt.)
Elindult az Indamedia média és marketing-kommunikációs kiadványa.
További szakmai tartalmakért kattints és kövess bennünket!
MEGNÉZEM
Kövesse az Indexet Facebookon is!
Követem!